简介:
Python爬虫及Python程序的第一弹。以知乎话题树爬虫为例尝试使用最原始的方法走通整个爬虫最基本的工作流程。包括模拟登录、页面数据获取、页面解析、判重、数据记录等步骤。以期熟悉爬虫最基本的工作原理。以及各模块的工作方式。
以跟话题为入口解析完整话题树并获取每个话题的话题名称、话题ID、关注人数、父话题名称、父话题ID以文件形式保存
知乎话题的URL为https://www.zhihu.com/topic/话题ID/organize/entire
一个用户可关注多个话题 一个话题可能含有多个父话题
一、模拟登录:
一些网站对于登录用户和非登录用户所提供的内容是不同的,或者非登录用户并不能获取正确的页面数据。
以知乎为例访问知乎首页已登录用户返回的是一些问题回答以及一些用户私有化操作的一些入口而未登录用户返回的是要求登录的界面。
网站典型的判定注册用户是否已经登录方式是通过Cookie而Cookie包含在http请求头中。因此只需要在请求页面数据的时候携带从已成功登录的浏览器中获取的自身的请求头即可。
以urllib2为例
1 | request = urllib2.Request(url,headers=config.mainheaders) |
需要携带headers信息
二、页面数据获取:
1 | # 获取页面内容 |
向一个URL发送请求并获取返回的数据这里可能包含多种异常例如页面不存在时会返回一个携带404状态码的HTTPError这里使用try except来捕获异常判断返回值类型来区分请求是否成功
三、页面数据解析:
获取的页面数据通常为HTML数据,我们需要从这些数据中识别到我们所关心的数据。
正则方式
对于结构易识别的数据可以采用正则表达式的方式从页面数据中直接获取以获取关注人数为例:
1 | # 获取关注人数 |
该正则表示从HTML数据中匹配<strong>标签下连续的数字。
调用成熟的HTML解析模块
对于结构复杂层级较多或者不易直接解析的的数据可以采用一些现有的成熟的HTML数据解析模块代替构建正则表达式的过程以获取父话题为例 父话题包含.parent-topic类同时包含一些其他的class、id、href等等信息,不易解析我们采用pyquery模块来解析获得的HTML代码获取’.parent-topic’类下的数据
1 | # 获取父话题 |
四、数据记录:
1 | # 记录话题数据 |
打开文件 并从底部添加内容记录解析到的话题名称、话题ID、关注人数、父话题名称、父话题ID
五、获取子话题:
根话题下包含一系列子话题例如’学科’、’实体’、’「未归类」话题’等通过在chrom下的开发者工具中Network模块在触发子话题请求时可以查到获取子话题的接口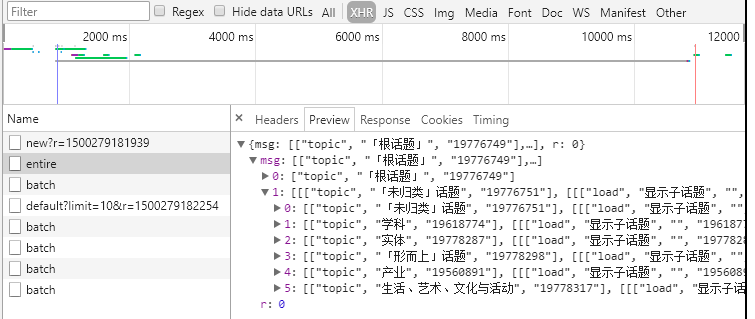
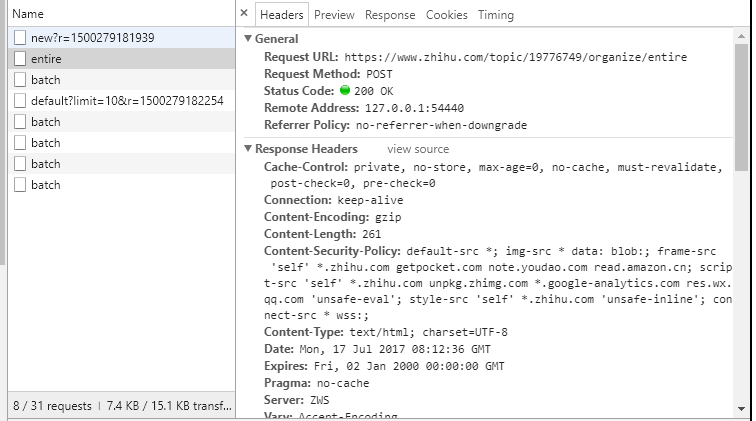
经分析可以发现该该接口的类型为POST、URL为一个携带该话题ID的串、携带的参数为一个会话ID并且会在header中出现、以及返回的数据结构、返回的数据一次性返回10个子话题如果子话题未获取完全可以URL中加入child参数继续获取认为当返回数据条数小于11时子话题已获取完毕。
代码
1 | # 检查子话题数据 |
六、抓取队列:
以根话题为例
- 记录根话题中感兴趣的数据
- 将根话题移出待抓取队列
- 获取根话题的子话题ID并压入待抓取队列。
- 检查抓取队列是否为空
- 从抓取队列中获取一个话题ID拼接成所需的URL
- 将该话题移出待抓队列
- 获取该话题的子话题ID并压入待抓取队列。
- 检查抓取队列是否为空
七、判重列表:
因为一个话题可能是多个话题的子话题。因此该话题可能通过多个话题被压入抓取队列,可能会被多次抓取。因此需要判重列表以判断该话题是否已经抓取。
1 | # 已抓取队列 用于判重 |
八、异常处理:
已发现的异常均为请求超时、获取的页面数据失败、解析失败。 采用try except来捕获异常并设置重请求次数。