概述
通过Kaggle脚本开始本次比赛
自行车共享系统是租赁自行车的一种手段,通过整个城市的信息亭网络,获得会员资格,租赁和自行车返回的过程自动化。使用这些系统,人们可以从一个位置租一辆自行车,并根据需要将其返回到不同的地方。目前(截止2013年年初),世界各地共有超过500项自行车共享计划。
这些系统产生的数据使得它们对研究人员有吸引力,因为旅行时间,出发地点,到达位置和时间已经被明确记录。因此,自行车共享系统可用作传感器网络,可用于研究城市的移动性。在这场比赛中,要求参赛者将历史使用模式与天气数据相结合,以预测华盛顿特区首都自行车赛计划中的自行车租赁需求。
任务
预测每月20日至月末每小时共享单车出租量。
训练数据
对于本次比赛,训练集由每个月的前19天组成
测试数据
测试集是月底的20日。您必须预测测试集所涵盖的每小时内租赁的自行车总数,仅使用租赁期之前的可用信息。
提交数据
您的提交文件必须有标题,并应以以下格式进行结构化:
| datetime | count |
|---|---|
| 2011-01-20 00:00:00 | 0 |
| 2011-01-20 01:00:00 | 0 |
| 2011-01-20 02:00:00 | 0 |
| … | |
| … |
字段名称
datetime -每小时日期+时间戳
season - 1 =春天,2 =夏天,3 =下跌,4 =冬季
holiday -无论白天被认为是一个节日
workingday -这一天是否既不是周末也不是假期
weather
1 : 很少云彩,部分多云,部分多云
2 : 雾+多云,雾+破碎的云雾,雾+少云,雾
3 : 轻雪,轻雨+雷暴+散云,轻雨+散云
4 : 大雨+冰托+雷暴+雾,雪+雾
temp - 摄氏
atemp - “感觉像”摄氏温度
humidity -相对湿度
windspeed -风速
casual -发起非注册用户租赁的数目
registered - 注册号码为注册用户租赁的启动-
count -总出租的数
开始
说明
数据分析第一弹,以最原始、初级、和低门槛化的想法入手以忽略数据细节不考虑结果的方式走通整个数据探查、数据分析、数据预测的整个流程。以期熟悉整个数据分析、数据预测的基本思考方式以及数据处理流程。
先用原始的思考方式解决有无问题,再用高阶主流的解决方案解决准确度问题。首次尝试不考虑一切影响因素仅从租出量数据入手尝试进行数据预测
第一次尝试——自然的分析方法
数据探查
正好Tableau还有10天试用时间,这里就使用该软件来实现基本的数据可视化以及数据探查工作。Tableau在可视化方面具有高效和快速的特点。适用于BI开发或者快速的可视化原型搭建。不过桌面端应用程序并不免费且收费较为高昂。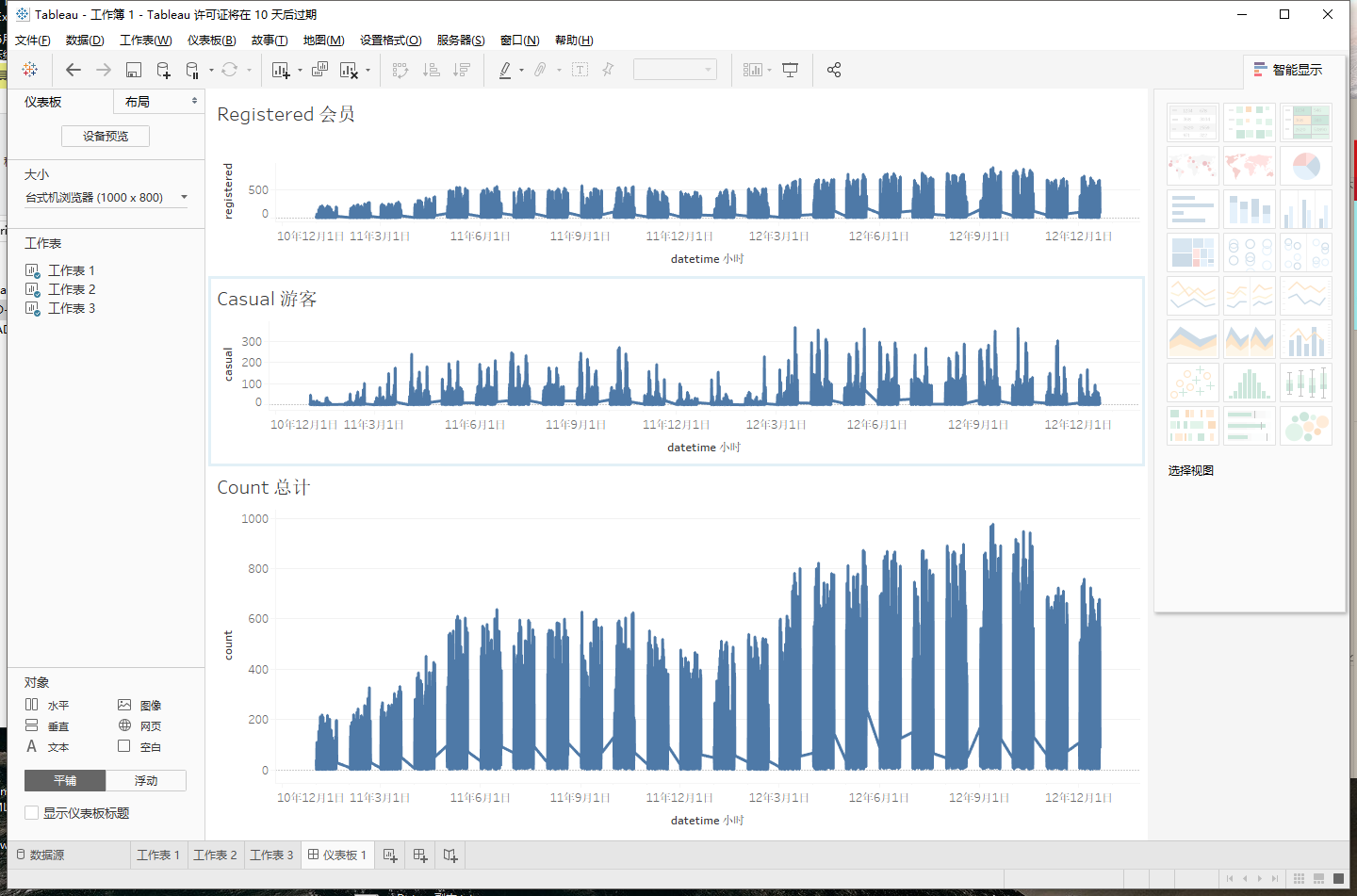
单以注册用户、非注册用户、以及出租总数而论。从图中可以看出非注册用户 整体以年为单位成周期性分布且有同比增长现象。注册用户整体呈增长模式季度差异较为明显。
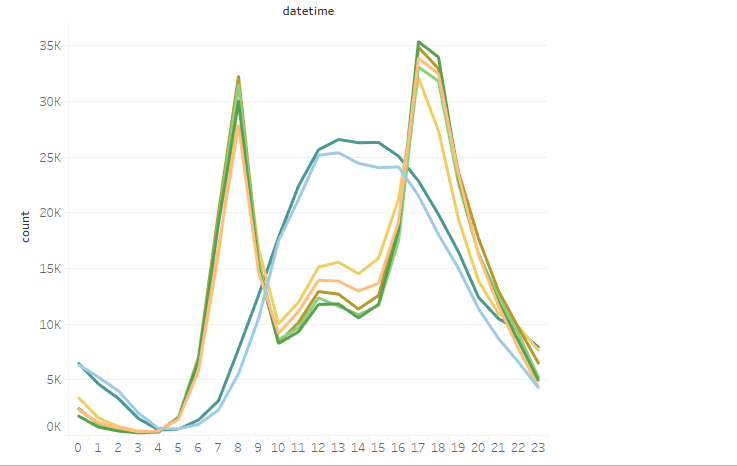
该图为每小时租出量的曲线图颜色代表星期一至星期日
假设与猜想
假设出租量与时间强相关、首先预测每日的出租量
假定每小时出租量贡献比例基本稳定,工作日每小时贡献比例一致、非工作日每小时贡献比例一致。
数据处理
预测每日的总出租量
主要流程
- 读取文件
- 统计每天的租出量
- 补充测设数据中的每月20日-月末的数据(补0)
- 获取拟合函数
- 保存每天租出量数据
由可视化结果初步假设租出量与时间的关系为一条4次曲线
这里采用python的scipy包进行作为核心计算模块matplotlib包作为可视化模块。
1 | # 获取拟合函数 |
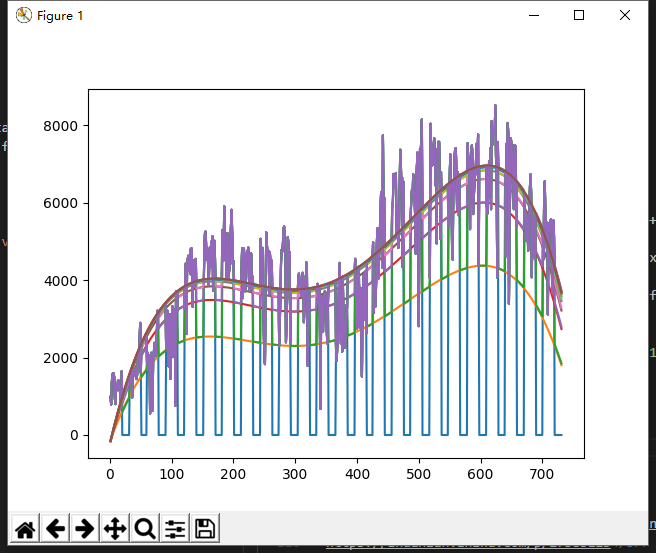
图中蓝色的线为原始数据,每月20日至月末数据为0。用原始数据进行拟合得到第一条曲线,将时间代入拟合函数计算待预测数据。将预测数据写入原始数据进行第二次拟合。
对图片进行局部放大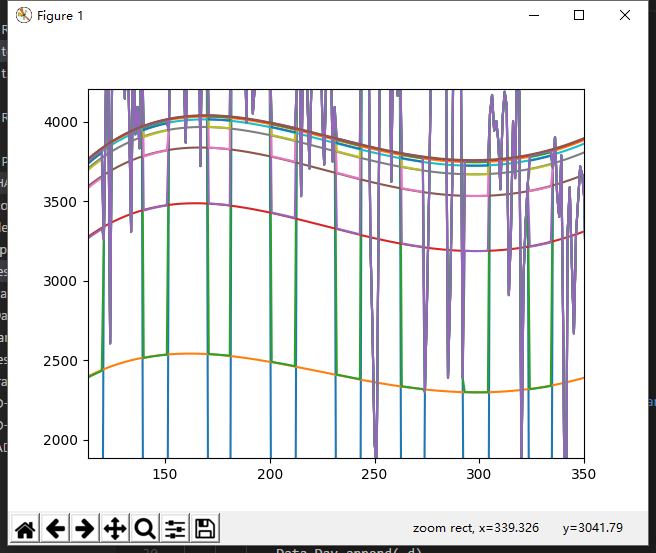
可以看出在第五次迭代之后拟合函数的变化程度已经不大,这里在迭代8次之后将预测数据保存得到每天的租出量数据。
预测每时的总出租量
- 将工作日与非工作日分类
- 计算工作日每小时租车量、总租车量
- 计算非工作日每小时租车量、总租车量
- 计算每小时租车量占总租车量的比例
- 预测每天租车量*每小时租车量占每天租车量的比例 得到小时租车量。
数据格式化与提交
提交数据必须为6494行,待提交数据某些天05点的数据缺失与计算出来的数据长度不符。将计算出来的数据和待提交数据匹配虑掉多余数据。
提交数据获得得分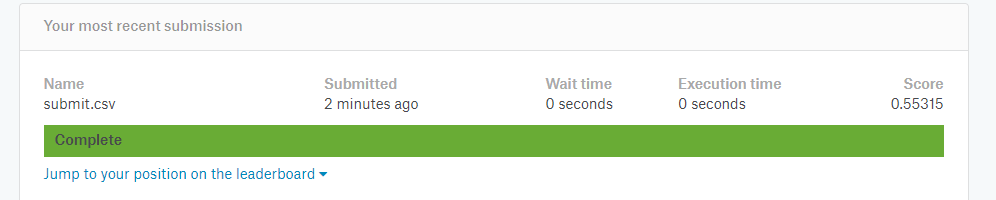
总结
这里仅考虑了时间对出租量的影响。主要包括一个数据维度(时间)两个参数(是否是工作日以及日期)。主要影响因素包括大时间跨度下用户的增长流失变化、随着季节的周期性变化。以及工作日和非工作日不同的出行模式。
给出的数据维度中、以传统的经验进行分析天气情况、温度、湿度、风速肯定会对短期的出租量造成一定的影响,由于第一次尝试以走通流程、熟悉思考方式为主要目标因此未考虑这些数据维度对数据预测所造成的影响。详细分析会在接下来的次尝试中给出
第二次尝试——默认参数的随机森林方法
说明
以跑通Pyhton sklearn包所带的随机森林算法为目的,采用默认参数预测数据并提交查看结果
这里将datetime数据转化成Unix时间戳作为一个参数压入随机森林算法进行预测
代码
1 | # 读取文件 |
数据格式化与提交
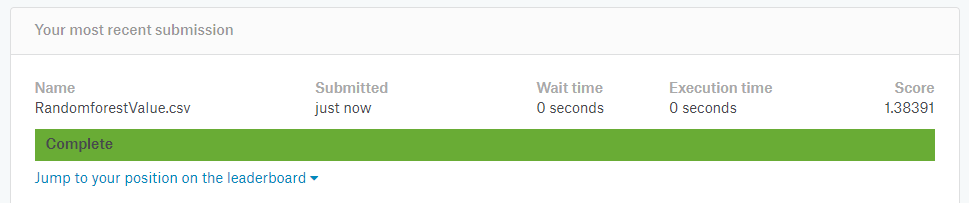
得分严重低于第一次尝试
尝试分析得分较低的原因
首先查看测试数据分布情况
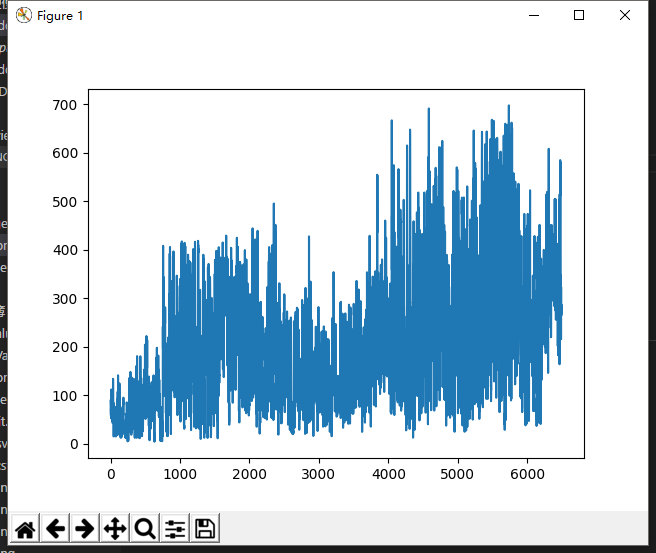
整体来说有增长趋势、离散程度在不断变大
将预测测试数据与训练数据结合查看分布情况
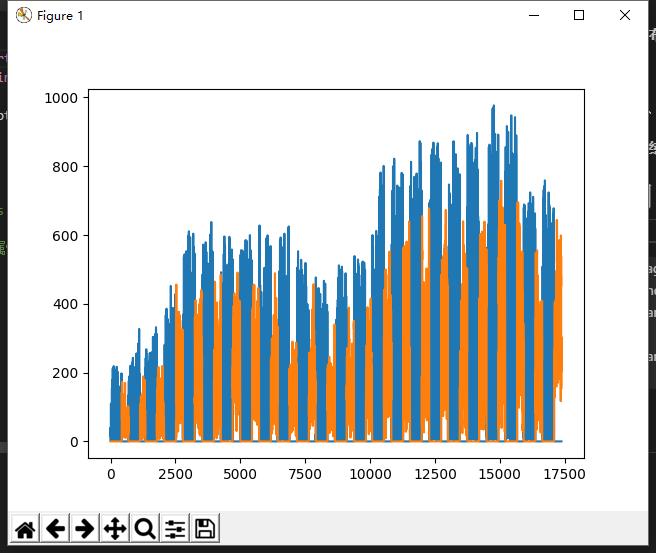
蓝色数据为训练数据橙色数据为测试数据,从图中发现预测数据相较于训练数据明显偏低
查看各个数据维度对分类的贡献情况

可以看出时间起到绝对贡献作用温度起到一部分贡献作用其余维度对结果贡献不大。是否休假维度贡献值为-0.001与经验完全不符
得分较低原因猜测
- Unix时间戳格式将年月日作为一个整体并没有对年、月、日、小时数据进行很好的分类
尝试将年、月、日、小时分开构建新的特征维度压入随机森林算法进行计算
将datetime的年月日维度进行拆分作为独立的特征进行计算1
2
3
4
5
6
7
8
9
10
11
12
13
14# _d.append(int(time.mktime(time.strptime(item['datetime'], "%Y-%m-%d %H:%M:%S"))))
_d.append(int(item['datetime'][0:4]))
_d.append(int(item['datetime'][5:7]))
_d.append(int(item['datetime'][8:10]))
_d.append(int(item['datetime'][11:13]))
_d.append(item['season'])
_d.append(item['holiday'])
_d.append(item['workingday'])
_d.append(item['weather'])
_d.append(item['temp'])
_d.append(item['humidity'])
_d.append(item['windspeed'])
X_Train.append(_d)
Y_Train.append(item['count'])
查看各个维度的贡献值
可以看出小时作为一个新的特征提供了绝对贡献作用,但是是否为休息日的特征维度仍为起到应有的贡献作用。原因未知(猜测分类器根据时间维度已经将是否为休息日做了简单的分类导致与是否休息日维度重合 存疑 希望有大佬解答)数据格式化与提交
评分结果已经优于自然分析法,不过相较于自然分析法优势并不是特别明显。但是采用随机森林方法在数据分析和数据处理上有很大的优势。可以在近乎不了解数据特征,未进行充分数据探查的情况下直接调用并且可以返回较为优秀的结论。降低开发门槛并且节省大量开发时间。
第三次尝试——尝试修改一些随机森林算法的参数再提交
修改部分参数
1 | rf=RandomForestRegressor(n_estimators=100,min_samples_leaf=5) |
这里将数目数量从默认的10调整到了100,将最小样本叶片大小从默认的1调整到了5来防止过拟合现象
数据格式化与提交

通过参数调整将评分从0.50+上升到了0.48+通过参数调整的方式并不能很好的提升预测结果的准确度。或者说受制于开发者技术水平限制无法对参数做出很好的调整。通过第一次尝试和第二次尝试评分差值与第二次尝试和第三次尝试评分差值对比发现,构建更好的特征对结果的提升要优于参数调整。
随机森林算法参数
http://sz-p.cn/blog/index.php/archives/54/
参考&引用
https://www.kaggle.com/c/bike-sharing-demand
https://zhuanlan.zhihu.com/p/27585123
https://zhuanlan.zhihu.com/p/27806864
http://blog.csdn.net/lulei1217/article/details/49583287
https://www.analyticsvidhya.com/blog/2014/06/introduction-random-forest-simplified/
http://scikit-learn.org/0.16/modules/classes.html
http://blog.csdn.net/lulei1217/article/details/49583287
http://blog.csdn.net/guotong1988/article/details/51568209