哈希表(HashTable) 定义 哈希表是基于键值对的一种数据存储结构,key值不可以重复,value可以重复,后面添加的重复的key值的时候,会把之前key值对应的value给覆盖掉,JavaScript中的对象具有天然的哈希特性 。
哈希表的常用方法:
put(key, value):向哈希映射中插入(键,值)的数值对。如果键对应的值已经存在,更新这个值。
get(key):返回给定的键所对应的值,如果映射中不包含这个键,返回 undefined。
remove(key):如果映射中存在这个键,删除这个数值对。
设计 hash表的实现普遍基于数组,将给出key 值映射到一个数组的一个地址 ,这里用一个hash函数来解决映射问题,hash函数存在两个问题,一个是性能问题,在大规模写入和查询时每次都会用到hash函数,另一个是冲突问题,key值可能是无限的,数组空间是有限的必然会出现多个key值 对应同一个地址的情况,称为hash冲突。我们来看一个简单的hashTable设计。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 function HashTable ( this .table = new Array (137 ); this .simpleHash = simpleHash; this .showAll = showAll; this .put = put; } function simpleHash (data ) { var total = 0 ; for (var i = 0 ; i < data.length ; i++) { total += data.charCodeAt (i); } return total % this .table .length ; } function put (key, data ) { var pos = this .simpleHash (key); this .table [pos] = data; } function showAll ( var n = 0 ; for (var i = 0 ; i < this .table .length ; i++) { if (this .table [i] != undefined ) { console .log (i + ': ' + this .table [i]); } } }
运行一下代码测试:
1 2 3 4 5 6 const hash = new HashTable ();hash.put ("Preshine" ,"Preshine" ), hash.put ("Clayton" ,"Clayton" ), hash.showAll () hash.put ("Raymond" ,"Raymond" ), hash.showAll ()
这里发现 我往哈希表中put了两个不同的key值 ‘Clayton’和’Raymond’,但这时候后者把前者的值给覆盖了,而且在数组中的存储坐标也一致,说明发生了哈希碰撞。
下面我们就稍微改进下散列函数:
1 2 3 4 5 6 7 8 9 10 function betterHash (str, arr ) { var H = 37 ; var total = 0 ; for (var i = 0 ; i < str.length ; i++) { total += H * total + str.chatCodeAt (i); } total = total % arr.length ; return parseInt (total); }
为了避免碰撞,首先要确保散列表中用来存储数据的数组其大小是个质数。这一点很关键,这和计算散列值时使用的取余运算有关。
这里定义了一个常量 H = 37; 这个质数37是一个比较好的数字适合我们的哈希算法来参与哈希键值运算,并且使生成的键值在哈希表中均匀分布。
应用新的散列键值函数后 就没有发生 碰撞了。
1 2 3 4 5 const hash = new HashTable ();hash.put ("Preshine" ,"Preshine" ); hash.put ("Clayton" ,"Clayton" ); hash.put ("Raymond" ,"Raymond" ); hash.showAll ()
即使再高效的散列键值生成函数也是有可能发生碰撞了,处理碰撞方法有很多中,这里我介绍2种方法。
开链法
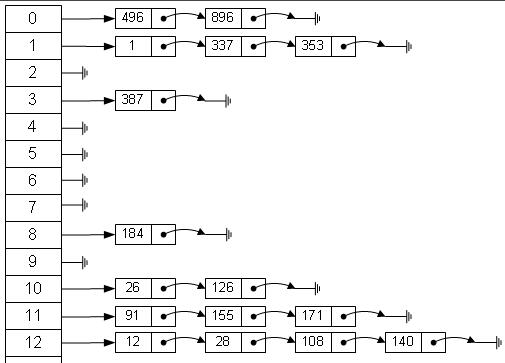
当碰撞发生时,我们仍然希望将键存储到通过散列算法产生的索引位置上,但实际上,不可能将多份数据存储到一个数组单元中。开链法是指实现散列表的底层数组中,每个数组元素又是一个新的数据结构,比如另一个数组,这样就能存储多个键了。即使两个键散列后的值相等,依然被保存在同样的位置,只不过它们在第二层数组中的位置不一样罢了,如图:
首先要初始化一下HashTable的数据存储结构:
1 2 3 4 5 function buildchains ( for (var i = 0 ; i < this .table .length ; i++) { this .table [i] = []; } }
下面给出put和get方法的代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 function put (key, data ) { var pos = this .betterHash (key); var index = 0 ; if (!this .table [pos][index]) { this .table [pos][index] = key; this .table [pos][index + 1 ] = data; } else { index++; while (this .table [pos][index]) { index++; } this .table [pos][index] = key; this .table [pos][index + 1 ] = data; } }
put的时候先算出哈希键值,然后在哈希表中查看是否有重复的哈希键值,如果没有重复的,则把值放入该位置,这时候数据是占用了数组的2个位置,是把key值存放之后,立即把值紧跟着存在后面;如果哈希键值有重复,则寻找到当前哈希键所在的哈希表的位置,然后在当前位置的数组中找到还没有利用的空间,然后把key值和value一起连续存储(其实就是JS数组的push()操作-_ - )。
get的时候就很简单了,就是一个把put过程取反的过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 function get (key ) { var pos = this .betterHash (key); var index = 0 ; if (this .table [pos][index] === key) { return this .table [pos][index + 1 ]; } else { index += 2 ; while (this .table [pos][index]) { index++; } this .table [pos][index] = key; this .table [pos][index + 1 ] = data; } }
2.线性探测法
如果数组的大小是待存储数据个数的1.5倍,那么使用开链法;如果数组的大小是待存储的数据的2倍及两倍以上,那么使用线性探测法。
采用线性探测法的时候,先给HashTable类初始化一个存储值的数组values = []; 存储键值使用table = [];
1 2 3 4 ... this .values = [];...
上面分析了怎么存储数据之后,我们来重写下put和get方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 function put (key, data ) { var pos = this .betterHash (key); if (!this .table [pos]) { this .table [pos] = key; this .values [pos] = data; } else { while (this .table [pos]) { pos++; } this .table [pos] = key; this .values [pos] = data; } } function get (key ) { var pos = -1 ; pos = this .betterHash (key); if (pos > -1 ) { for (var i = pos; this .table [pos]; i++) { if (this .table [pos] === key) { return this .values [pos]; } } } return undefined ; }
照着前面的思路把数组给存进去之后,在拿的时候,只需要算出键的哈希值,在table中从pos坐标开始遍历,找到存储key值的坐标后直接用当前return values[pos];就拿到存入的数据了。
最后要注意哈希表哈希算法的计算复杂度和计算时间,哈希函数也正是哈希表的精髓所在。基于key-value数据结构存储的应用非常广泛,因为使用它非常方便,效率和很高,常见的有很多基于key-value存储的应用,比如redis数据库等。
实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 function HashTable (this .hashKey = 33 ;this .hashLength = 137 ;this .key = new Array (this .hashLength );this .value = new Array (this .hashLength );} HashTable .prototype _showAll = function (for (let i = 0 ; i < this .hashLength ; i++) {if (this .key [i] !== undefined ) {console .log (`${i} ${this .key[i]} :${this .value[i]} ` );} } }; HashTable .prototype hash = function (key ) {var index = 0 ;for (var i = 0 ; i < key.length ; i++) {index += this .hashKey * index + key[i].charCodeAt (); } index = index % this .value .length ; return parseInt (index);}; HashTable .prototype get = function (key ) {let index = this .hash (key);while (this .key [index] !== undefined && this .key [index] !== key) index++;return this .value [index];}; HashTable .prototype set = function (key, value ) {let index = this .hash (key);while (this .key [index] !== undefined ) index++;this .key [index] = key;this .value [index] = value;}; HashTable .prototype remove = function (key ) {let index = this .hash (key);while (this .key [index] !== key) index++;this .key [index] = undefined ;this .value [index] = undefined ;};
应用 由于js对象自带hash特性 而且hash应用其实非常多 这里就不特别举例了。
见705. 设计哈希集合
参考 & 引用 https://blog.csdn.net/PingZhi_6766/article/details/78025313