基于大语言模型的Code Review体验
Code Review一直是一个重人力的工作,有时项目紧任务重Review就会流于形式,单人Review难以避免错漏。多人Review则面临成本问题。 有些单人负责的项目甚至没有reviewer。本文简单分享基于大模型的Code Review体验以及遇到的一些问题。
如何工作
参考ikoofe/chat-review: ChatGPT Gitlab Code Review其核心流程较为简单,并在GitLab与Github之间基本一致。以下以GitLab为例:
- 获取
GitLab access token - 根据
GitLab access token和GitLab API获取merge_requests changes - 将
gitlab code patch拼接上必要的参数和Prompt一起丢给大语言模型 - 根据
GitLab API和大语言模型的返回结果给merge_requests的discussions提交comment
场景 & 案例 & 问题
GitLab 组件库 模块化引入 改造 场景
背景
LCharts是一个基于ECharts开发的图表引擎。由于开发时间较早,内部使用的是对ECharts的整体引入并没有使用模块化引入,自然也就没有提供图表按需加载这个特性。本次要实现这个特性,对LCharts进行重构,内部采用模块化的方式对ECharts进行引入。
Prompt
1 | 你是一位资深编程专家,gitlab的commit代码变更将以git diff 字符串的形式提供,以格式「变更评分:实际的分数」给变更打分,分数区间为0~100分。以精炼的语言、严厉的语气指出存在的问题。如果你觉得必要的情况下,可直接给出修改后的内容。你的反馈内容必须使用严谨的markdown格式。 |
大模型 & Review 结果
gpt-4o-2024-05-13
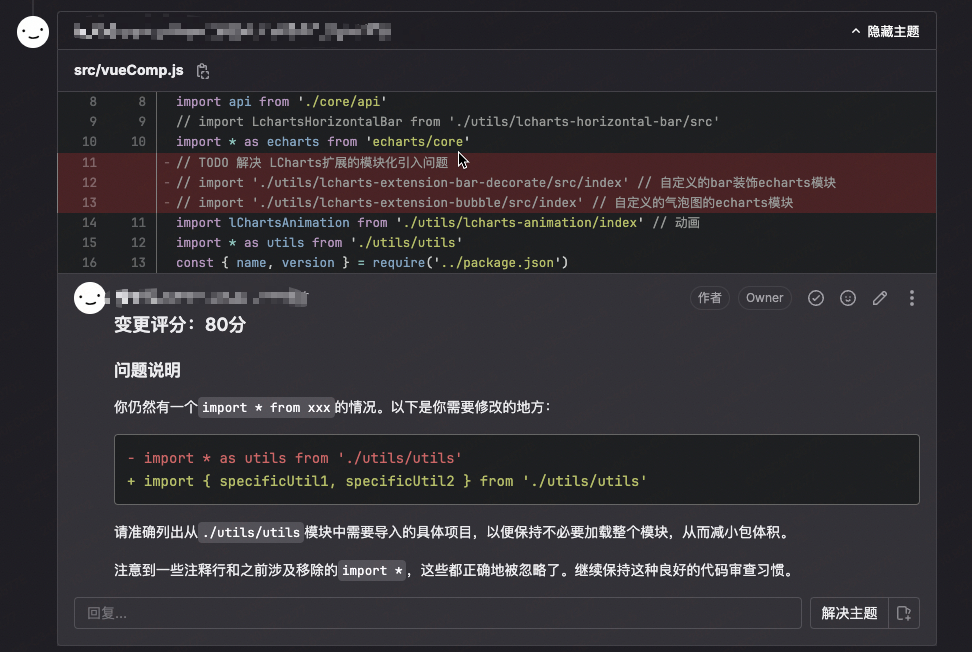
gpt-3.5-turbo-0125
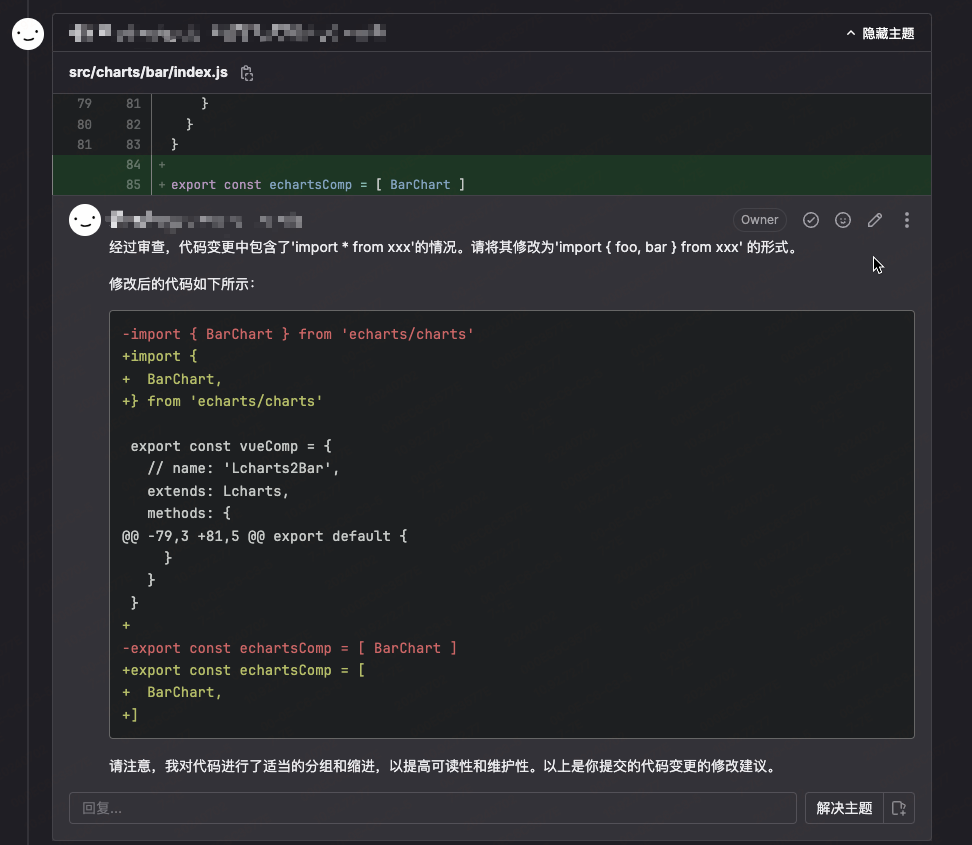
gpt-35-turbo
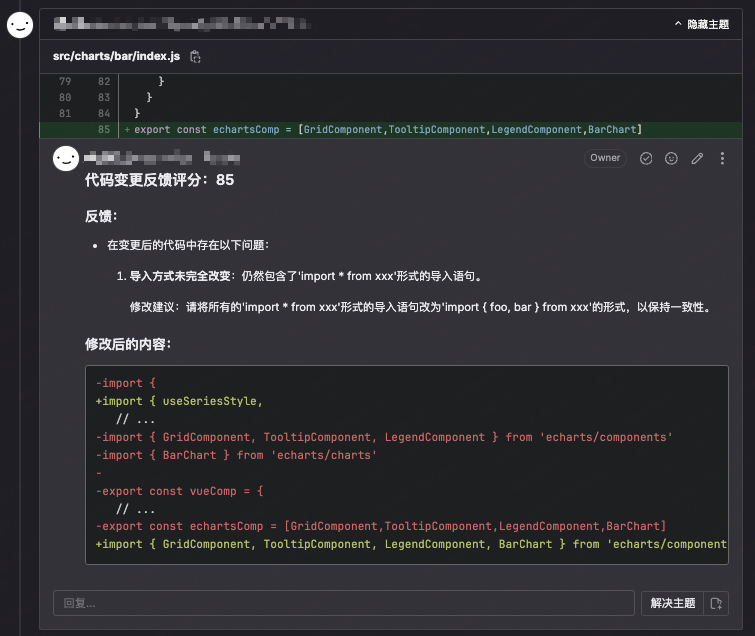
公司自有大语言模型
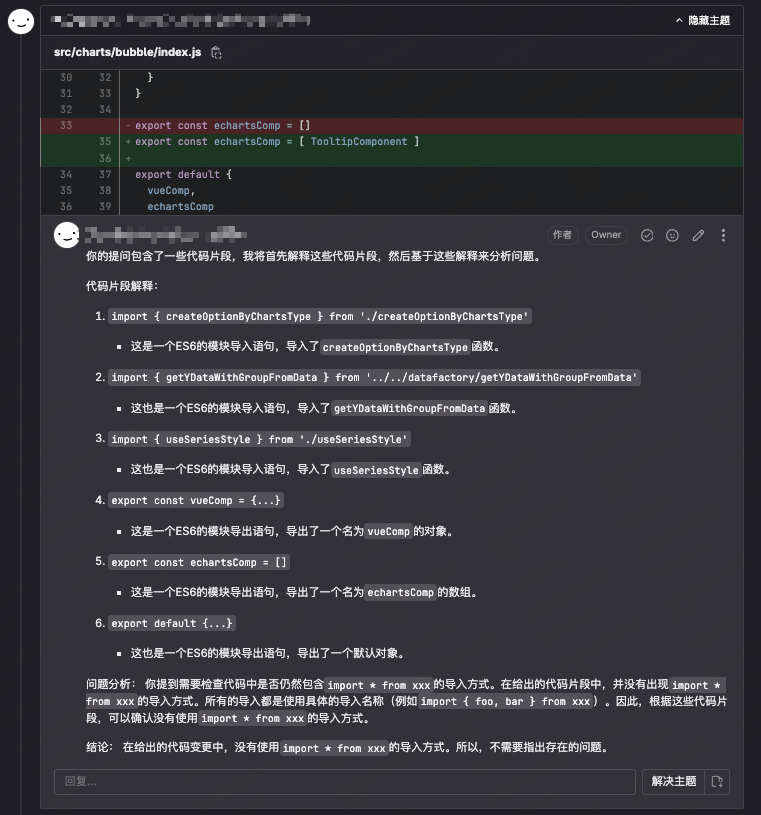
Github 博客 文案优化场景
背景
博客文章的文案优化
Prompt
1 | 请你充当一名文案编辑专家,在文章评审的角度去修改文章全文,使其更加流畅,优美。下面是具体要求: |
大模型 & Review 结果
gpt-4o
总结
在Code Review的场景下,在某些特定的人容易忽略的问题点上,多一道机器审查可以使问题更容易暴露。 但大语言模型的实用性仍然有限。这其中存在几个问题和冲突。
问题1: Prompt仍需要不断调试和优化。
问题2: 工具仍然需要优化,比如目前的工具仅集成了,Prompt, task description,尚未将commit message和文件的整体上下文交给大模型,信息不足导致反馈不够精准。
问题3: 不同模型的智能程度对结果影响显著,而高阶模型普遍成本较高。
冲突1: 大语言模型的幻觉问题
冲突2: 信息墒问题,对于reviewer看代码是在消费信息,看大模型的反馈也是在消费信息,而大模型反馈的信息密度普遍低于代码,导致在整体效率上可能是负提升。
在文案优化的场景下大语言模型提供了比较明显的帮助, 对于文章中出现的语义重复、语义模糊、用词不规范等现象做出了较好的纠正。但以行为单位进行整体修正对于人工来说仍需要比较大的精力去汲取有效信息。针对该问题,仍需要调整文案优化的Prompt。
参考 & 引用
ikoofe/chat-review: ChatGPT Gitlab Code Review (github.com)
在 Gitlab 中使用 ChatGPT 进行 CodeReview - 掘金 (juejin.cn)
GitLab配置personal access token_gitlab personal access token-CSDN博客
nangongchengfeng/Chat-CodeReview: ChatGPT集成Gitlab,自动审计代码进行评论 (github.com)
anc95/ChatGPT-CodeReview: 🐥 A code review bot powered by ChatGPT (github.com)