海伦公式
$$ S = \sqrt{p(p-a)(p-b)(p-c)} $$
假设在平面内,有一个三角形,边长分别为a、b、c,三角形的面积S可由以下海伦公式求得,其中p为半周长(周长的一半)$p=\frac{a+b+c}{2}$
凸包算法其实是一个挺常用的算法,例如在这道题(812.最大三角形面积)中,常规的解决方案就是写一个时间复杂度O(N^3)的暴力算法去枚举所有可能出现的三角形,再利用海伦公式去求得三角形面积。不妨我们大胆假设,在一堆点的集合中,其中面积最大的三角形的顶点,必然位于这些点的凸包上。论证我们先跳过,直接用结果去验证假设是否成立(经验证,假设是成立的)
凸包算法有很多种,例如
这里详细介绍常规的 Graham扫描法,Graham扫描法时间复杂度优于Jarvis步进法,理解起来稍微比之困难一些,但影响不大。
泛洪算法——Flood Fill,(也称为种子填充——Seed Fill)是一种算法,用于确定连接到多维数组中给定节点的区域。 它被用在油漆程序的“桶”填充工具中,用于填充具有不同颜色的连接的,颜色相似的区域,并且在诸如围棋(Go)和扫雷(Minesweeper)之类的游戏中用于确定哪些块被清除。泛洪算法的基本原理就是从一个像素点出发,以此向周边相同或相似的像素点扩充着色,直到周边无相同颜色的区块或到图像边界为止。
泛洪填充算法采用三个参数:起始节点(start node),目标颜色(target color)和替换颜色(replacement color)。 该算法查找阵列中通过目标颜色的路径连接到起始节点的所有节点,并将它们更改为替换颜色。 可以通过多种方式构建泛洪填充算法,但它们都明确地或隐式地使用队列或堆栈数据结构。
机器学习的算法相对都比较抽象,需要一定的数学功底,这里简单的列一下机器学习算法学习思路,这个应该按照什么个流程去学习收获最快。
流程: 目的→输入输出→思想→流程→代码→原理→数学依据。
大白话版:干啥的→干了啥→怎么干→为什么可以这么干。
大致可以按照上述流程去执行。
首先了解这个算法的目的,解决他是干啥的这个问题,再去了解它的输入输出,这其实是解决了它干了啥这个问题。到这里算是解决了这个算法怎么用的问题,做到了能用。
了解完它的输入输出之后可以去了解这个算法的思想,执行过程、代码。这部分可以总结成怎么干。到这部分其实算是对算法有了一个具体认知。知道数据集和各个参数具体对结果造成了那些影响。算是做到会用。
之后可以尝试了解算法的原理,看懂数学公式算是了解原理,理解推倒过程算是了解数据依据。这一大步是在解决为什么可以这么干的问题。这一步走完算是掌握
每一个搞web开发都需要了解的知识,长期更新不断完善
解析URL解析URL的协议名,域名,端口号,路径,查询参数(?),哈希值(# )等。
DNS解析如果有相应的浏览器缓存或本地缓存,则直接使用缓存,不进行DNS解析。如果没有相应的DNS缓存,则访问DNS服务器,进行DNS解析,查询出域名对应的IP地址。
建立TCP/IP连接:通过三次握手建立与服务器的连接(长连接或短连接),在此之后发送具体的请求到服务器,等待服务器的响应。浏览器根据请求作出应答,返回数据包。最后当关闭连接时,双方进行通过四次挥手断开连接。
浏览器的主要功能就是向服务端发送请求,下载解析资源显示在浏览器上。将网页内容展示到浏览器上的过程,这其实就是渲染引擎完成的。渲染引擎有很多种,这里以 webkit 为例。
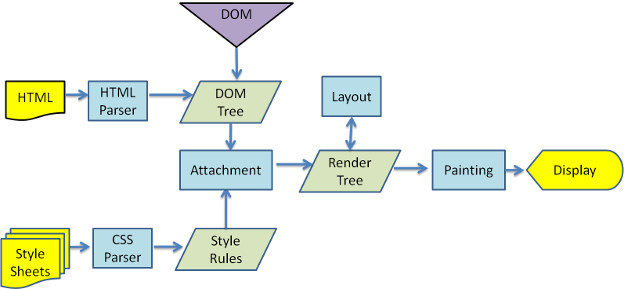
从上面这个图上,我们可以看到,浏览器渲染流程如下:

